Sparkle: ML-based medication adherence
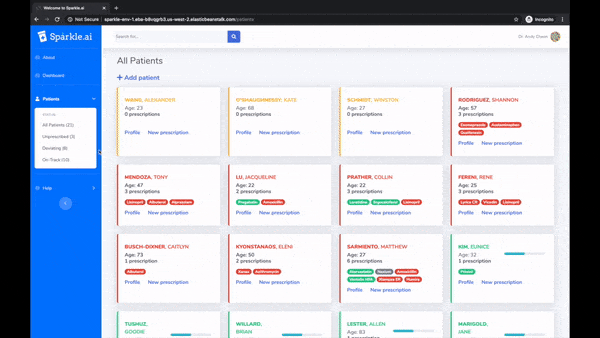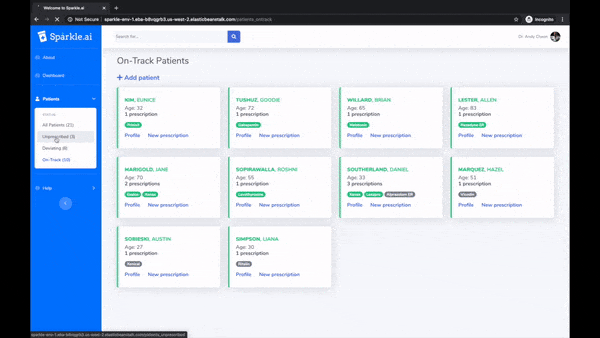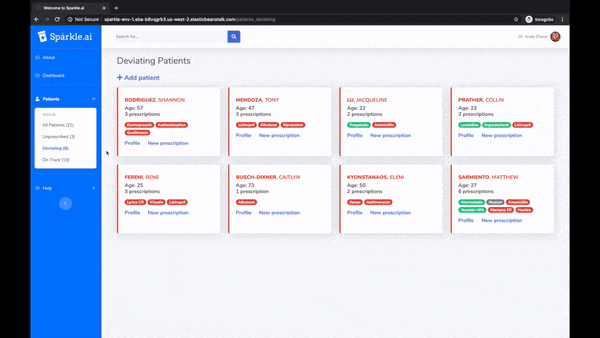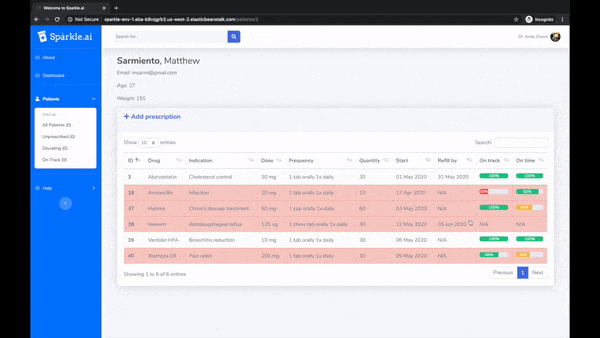
Many people simply fail to take prescribed medication. It's costly to both their health and the healthcare system. Sparkle is a platform consisting of AppleWatch, iOS, and web apps to encourage patients to stay on track, and to allow doctors to monitor progress. At its core is a machine learning model trained on smartwatch sensor data to verify medication intake motions.
Our paper was accepted to the IEEE Engineering in Medicine and Biology Society Conference 2020, Montréal.
GitHub repository
Tools used: scikit-learn, XGboost, PySpark, Flask, AWS, PostgreSQL, Docker